


This AI recognises Bangla speech and text


Nowadays, while we tend to use Google Translate to quickly turn everyday English into Bangla and call it a day, the accuracy of the translation might be far from perfect. Native speakers tend to find notable flaws in AI-generated translations, and many would even claim that AI lacks the fluency and touch of conversational language, especially Bangla - a language filled with many different regional dialects that are quite different from the more standardised written form that we are used to.
So is it simply not possible to teach AI conversational, everyday Bangla in spoken and written form? While we may not have reached a definitive answer to that question yet, there is a certain language project going on that tackles this exact conundrum.

The Bangla speech recognition campaign
Founded in December 2017 by a group of BUET, KUET and BRACU graduates, Bengali.AI is a voluntary research initiative that aims to democratise AI research in Bangla by teaching AI the Bangla we use every day. By looking into how computers read, speak and understand language, this non-profit initiative creates large-scale machine learning datasets to teach AI the complex yet beautiful Bangla language. Their datasets, collected from various Bangla-speaking demographics, are made available to researchers for free to help train artificially intelligent systems.

Bengali.AI's currently ongoing project on Bangla speech recognition has produced the largest publicly available Bangla speech corpus. As diversity is a key part of building a conversational Bangla dataset, Bengali.AI is aiming to collect voice data from as many people as possible. Right now, they are running a special campaign on social media called 'Bok bok', where Bangla speakers from anywhere in the world can contribute their "voice data" for the public domain research dataset.
How to participate in 'Bok bok'
To contribute, simply login to the contribution platform and start reading the sentences that appear on the screen, loudly and clearly. As a token of your contribution to this constant development of the Bangla database, Bengali.AI awards an honorarium to anyone who contributes. If you want to participate, simply follow the procedures in this link: https://commonvoice.mozilla.org/bn/speak
According to the Coordinator of Bengali.AI, Asif Sushmit, since February 21, 2022, the Bangla speech recognition campaign has gathered around 2,000 hours of data from over 22,000 people - the standard benchmark for training industry-grade speech recognition models. They aim to achieve a higher landmark of 10,000 hours to include more nuances and diversities of the language so that researchers can train their own AI better.

Bengali.AI plans to use this voice data to fine-tune the conversational aspect of the language AI and build a publicly available automated speech recognition system. In theory, this AI will be able to understand conversational Bangla similar to Alexa and Siri, with the added benefit of being tweaked by anyone, anytime, free of cost.
Other projects
Bengali.AI's journey began in 2018 with NumtaDB, a dataset containing over 85,000 images of hand-written Bangla digits. The dataset was compiled to build Bangla digit recognition algorithms that are free of geographical, gender and age-based biases.
In 2020, the Bengali.AI team published the first-ever dataset of over 500,000 handwritten Bangla graphemes, and launched an international Kaggle competition in collaboration with Google. This competition had over 2,000 teams from all over the world, regardless of their native tongue. These teams consisted of some of the biggest names in AI like NVIDIA and H20.AI - all joining forces to solve optical character recognition for Bangla.
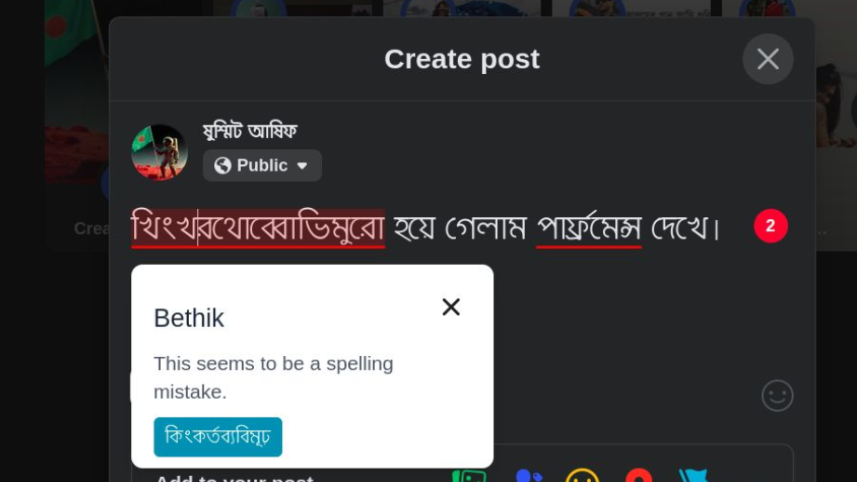
By 2021, Bengali.AI launched many side projects, all catered towards the advancement of machine learning and natural language processing of the language. Some of these publicly available projects include: a Bangla dictionary that can automatically analyse speech annotation, a transcriber aimed towards transliterated or "Murad Takla" Bangla text, and Bethik - the opensource Bangla spell checker that can spot and fix high-degree Bangla typing errors. Made by a team of 40 students from SUST and BRACU, as well as voluntary researchers from many different fields, Bethik will be made publicly available within the next month.
Currently, Bengali.AI is a community of over 6,000 international researchers who are all working towards achieving what many deem impossible: democratising Bangla language-related technology. By making everything open source, publicly accessible and 'rectifiable' - an important part of the recipe, the lack of which has led to the downfall of similar projects in the past - Bengali.AI wishes to help make technology accessible to anyone 'Bangla'. With their ever-expanding database of Bangla derived from thousands of native speakers, we may be on the path towards an AI we can speak everyday Bangla with.
 For all latest news, follow The Daily Star's Google News channel.
For all latest news, follow The Daily Star's Google News channel. 



Comments